Above is a partial output of the original 2020 “bot” defender model when applied to mentions of “Biden” on Twitter in during the primaries.
What is the Problem?
People reading social media posts tend to believe what they already believe or disbelieve what they already disbelieve. They may never bother to verify the facts or the source. Taking even a few seconds to verify a statement or the amplifying source might have a surprising effect. How can we encourage students to take those few extra seconds? We have put together a framework called TrustDefender that might make verification both educational and fun.
What is it?
TrustDefender is a free information literacy and digital citizenship platform. We recognize the importance of digital-literate citizens. This platform could help some first-time voters. We hypothesize that having students take a few extra seconds to dig into the digital footprint of a Tweet will impact trust. Given this is my fourth decade of research, I know the results are going to be unpredictable with unintended consequences. Such is the history of information. Sign up for TrustDefender and help us figure this out.
What is the background story on TrustDefender.net?
We are updating DiscoverText, a free web-based scientific research instrument, to explore gamification. Scholars use DiscoverText to search, filter, cluster, annotate, and machine-classify text data. Diverse scholars have published more than 600 research papers using these five pillars of text analytics. Specific game-oriented modifications to the annotation platform launched as TrustDefender on August 27, 2024.
Is TrustDefender a game?
We are not sure yet. In recent meetings with a variety of scholars and gamification experts, the question was not resolved. Some of the measurement tools and methods were originally designed in 2007 as open source software and later developed as DiscoverText starting in 2010, and patented in 2016 under the title “System and method of classifier ranking for incorporation into enhanced machine learning”. The core annotation mechanism loads data automatically and allows annotators to record observations with a single keystroke.
We sought to understand the challenge of crowdsource annotation (ex., speed, consistency, domain knowledge, inter-rater reliability, gold standard validation, and “CoderRank“) each of which have elements amenable to leaderboards, novel rankings, and competition. We have come to see Twitter itself as a live game platform. User behavior backs this up. Players across the political spectrum seek to game the system to earn status, influence, and power. We are trying to adapt, test, and possibly modify the rules of the game known as Twitter.
What is the data?
We are using existing and new custom Twitter datasets ranging from tens of thousands to several million curated Tweets. Some of the historical data include #metoo, #BLM, Trump, Biden, Flynn/QAnon, digital soldiers, AmericaFirst, Canadian elections, the Canadian trucker convoy, Canadian migration, and other important windows into the trust conundrum in North American politics.
What is the goal of creating TrustDefender?
One goal is to better understand how DiscoverText can be modified to have default, ready-to-play games, as well as the traditional framework where it is simply a flexible tool, like a spreadsheet. Leaders of the games will also be able to create new tasks, codes, rules, parameters, code books, assignments, peer groups, and focus the students. Much of the content of the games can be created by the professors or teams of students.
Can you create new custom datasets using summer and fall queries?
Yes, we have worked with academics regularly since 2010 to acquire custom datasets relevant to the themes central to their classrooms and research. We also provide free training.
What are some examples of games?
There will be archetypal game formats such as the deductive “live, deleted, suspended” and hybrid deductive/inductive “trust, don’t trust, need more info” games. The core of this experiment is what students will see when they indicate that they “need more info” having been unable to trust or distrust a Tweet at first glance. The drill down will include adaptable options to quickly review the user profile page, as well as the follower and following lists.
More fully inductive games such as “bot, troll, or citizen” are possible. Small adaptations of the existing crowdsource software will make the labeling task more game-like in TrustDefender. Students will train or play on default games out-of-the-box that are easy to launch, but professors will also be able to adapt the framework with very minor effort to define parameters for their own games.
How long will it take to set up?
There will be a very simplified onboarding process for creating new tasks or games, loading student lists, connecting students as peers within a class, and sending out tasks as homework.
How long will a task or game take?
That is up to the professor. We envision a wide variety of labeling tasks as short as 2-3 minutes or as long as it takes. Certain tasks produce conceptual saturation in a few minutes. Others require the classic deeper dive.
Will there be deidentification options for the leaderboards in games with ranked outcomes?
Yes, though every student will know where they wound up when there is, for example, a speed or accuracy ranking, as there will be in Live-Deleted-Suspended games.
How long does it take to be fluent with the TrustDefender platform?
Most people self-train on DiscoverText, but I strongly encourage you to book a meeting here and take the 30-minute TrustDefender training. You can still help to shape how this application works and improve the core ideas. It is an adaptable framework to inspire innovation not a rigid prescription of how to measure trust.
Is there a scientific underpinning to the exercise?
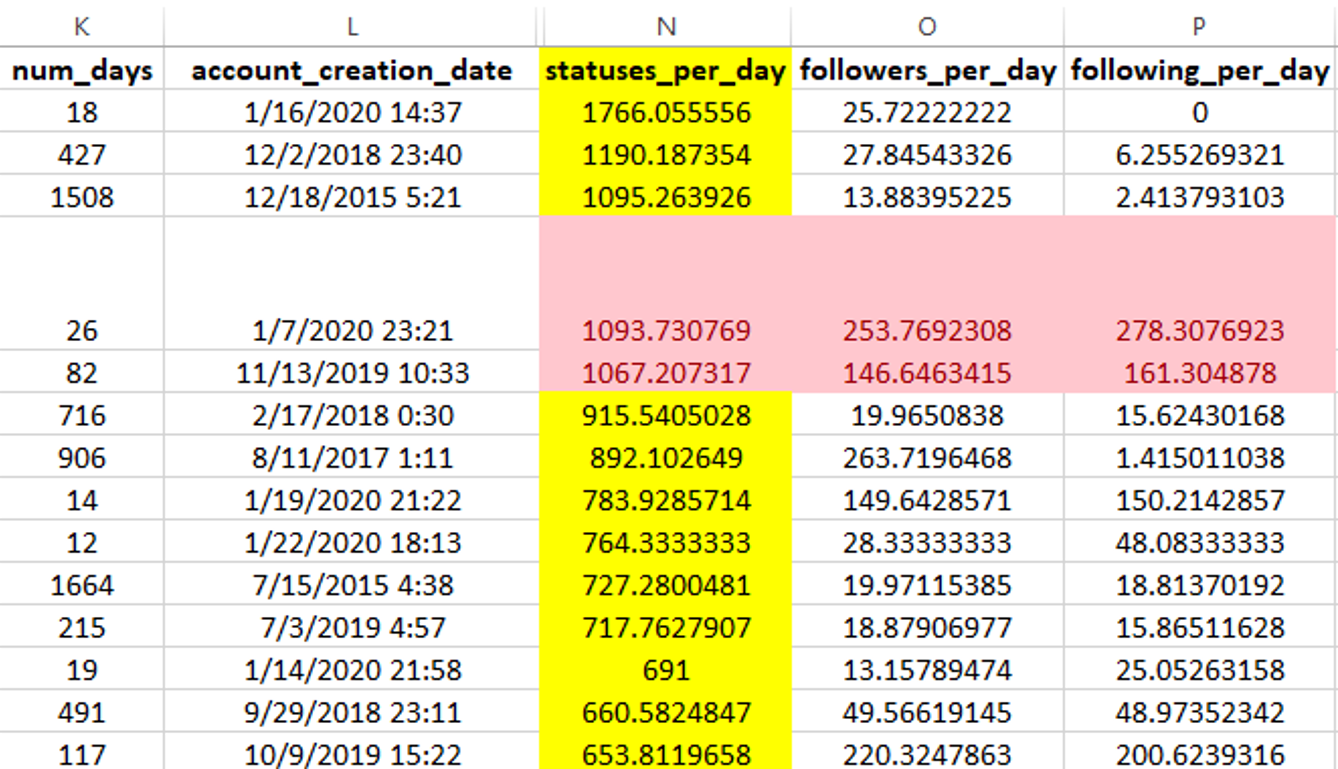
Definitely. For example, we are creating a framework for dividing students in a class into control and experimental groups. The goal is supporting professors interested in testing the impact on trust in control and experimental groups where: some get visibility to select metadata (experimental groups) some don’t (the control groups), or some get visibility to just highly influential accounts (experimental groups) some don’t (the control groups), some get visibility to just marginal accounts (experimental groups) some don’t (the control groups). The number of possible permutations is large, and we don’t think we have figured this all out. As an observer, when I am aware of just these three data points about a user, (1) statuses per day, (2) following per day, and (3) followers per day, it impacts my trust evaluation.
Can professors and students use the data to publish their own scholarship?
Absolutely. We want to generate many experiments in September and October 2024 so that professors and students can use their class data to publish blog posts, findings on social media, and scholarly research papers.
For more information:
Dr. Stuart W. Shulman
Founder & CEO, Texifter, LLC
stu@texifter.com